Data Integrity Strategies for Patient Matching, Identification
Patient matching is a critical safety concern. How can providers boost their data integrity to improve their accurate identification rates?

Source: Thinkstock
- Patient matching errors are an insidious but all-too-common threat to patient safety in the healthcare setting. While providers have generally embraced the idea that a patient’s electronic record should follow her from the moment she steps into the office until the last time she has contact with a clinician, an individual’s journey along the care continuum often starts with a data integrity misstep.
Typos, missing information, workarounds, and data entry quirks can result in duplicated or inappropriately merged records that pose significant problems for clinicians who rely on accurate and complete data for making informed decisions about care.
In the absence of a national patient identifier – a contentious issue for privacy advocates – healthcare organizations have generally been left to their own devices to figure out how to ensure that their health IT systems can correctly identify patients as they move between locations and care teams.
Unfortunately, the lack of a unified, industry-wide approach to patient identification and matching has resulted in a high rate of errors – many of which result in some degree of real or potential patient harm.
A 2016 Ponemon Institute survey of more than 500 respondents found that 86 percent of participants have witnessed or known about a medical error that occurred as the result of patient misidentification.
Data integrity issues don’t just put a patient’s health at risk. Reimbursement rates and patient satisfaction scores are also in the line of fire.
More than a three-quarters of respondents said that inaccurate patient identification contributed to up to half of their denied claims. Eighty-four percent said it takes up to an hour for staff to coordinate with the health information management (HIM) department to correct a patient ID problem.
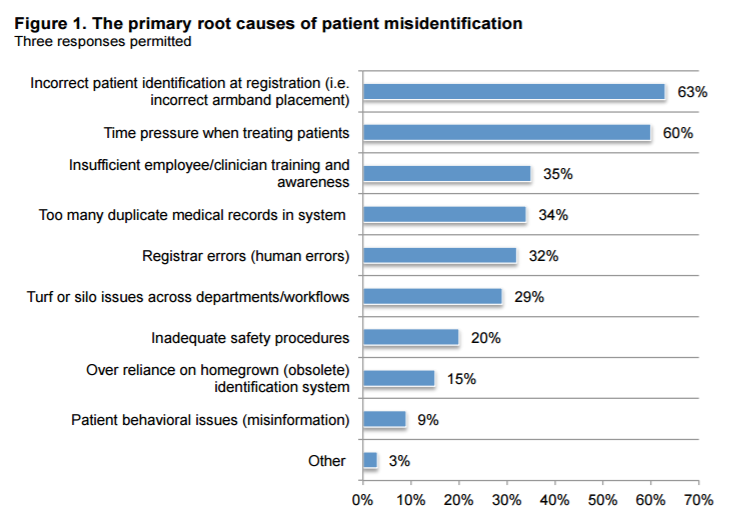
Source: Ponemon Institute
Close to two-thirds of participants said that patient identification issues begin at registration and snowball after a new record is added to the enterprise master patient index (EMPI) or other patient database.
Thirty-four percent of respondents said that duplicated records were to blame, while a similar number tapped human error as a major concern. Fifteen percent added that an overreliance on an obsolete identification system contributed to misidentification mistakes.
READ MORE: Preventing Big Data Pain Points During a Healthcare Encounter
The problems are only multiplying as value-based care contracts and population health management strategies encourage disparate health systems to share patient data, said Ben Moscovitch, Manager of Health IT at The Pew Charitable Trusts.
“Patient matching is one of the critical pillars of interoperability,” he said. “It’s very difficult to effectively exchange information among healthcare facilities without knowing which records should be linked together and which should remain separate.”
“There’s quite a bit of variability in how providers address patient matching and the algorithms they choose to help them. Enhancements to patient matching techniques will be necessary for realizing an interoperable healthcare system.”
Why current patient matching strategies are falling short
Existing patient matching techniques tend to rely on probability. Using a number of demographic data elements, such as a patient’s name, address, Social Security number (SSN), and birthdate, an algorithm identifies the likelihood that a given record matches a given individual.
But not every system uses the same number or type of variables, and not every provider has a high enough level of data integrity to feed these algorithms with the information they need to get it right every time.
As far back as 2008, RAND Corporation cautioned providers that using an insufficient number of patient attributes could result in significant numbers of records being inappropriately identified as belonging to the same individual, which is known as a “false positive.”
“Our analysis of an 80-million-record demographic database indicated that an error-free composite key made up of name, date of birth (DOB), zip code, and last 4 digits of the SSN would be required to unambiguously identify all patients,” the organization said at the time. “Removing the partial SSN from the key creates nearly 1000 false positive matches in this database.”
Even sophisticated algorithms can struggle with certain patient populations. Pew notes that in the Harris County health system, which includes Houston, Texas, nearly 2500 patients share the name “Maria Garcia.” More than 230 of those people also have the same birth date.
Both false positives and false negatives – when two records for the same individual are kept separate – are likely with a patient pool that exhibits unusually high rates of similarities.
Also at risk for insufficient identification are populations with high degrees of housing instability or homelessness as well as communities that are missing key unique identifiers, such as recent immigrants without Social Security numbers.
READ MORE: The Role of Healthcare Data Governance in Big Data Analytics
Some organizations have tried to improve their chances of a correct match by collecting as much demographic data as they possible can, said the Office of the National Coordinator.
“Organizations had an interest in historical demographics such as previous names, addresses, or phone numbers,” the agency wrote in a 2014 report after collecting feedback from stakeholders. “Mayo [Clinic], for instance, has been trying to collect maiden name at its Rochester site and in other areas is trying to standardize previous name.
“Some systems already collect previous data attributes, but others do not or cannot. Geisinger [Health System] believes that using mother’s maiden name for matching might be possible, but patients may not know it, know how to spell it, or be willing to share it. Additionally, some hospital information systems may not have a field available for an additional attribute such as mother’s maiden name.”
All of these difficulties can be magnified for a provider trying to engage in health information exchange (HIE) with other partners in the area. Up to half of potential patient matches can be incorrect when organizations attempt to seek records from other facilities, Pew said.
Even entities using the same electronic health record vendor can suffer from a precipitous decline in correct matches when querying across organizational lines, the ONC pointed out.
“For example, Kaiser Permanente (which has 17 instances of Epic across its regions) reported a match rate of greater than 90 percent within each instance; that rate fell to around 50 percent to 60 percent when sharing between regions using a separate instance of Epic or with outside Epic partners,” the report said three years ago. “Other organizations cited similar declines in match rates as data is shared across unaffiliated organizations.”
There is also the human factor. Incorrect input on the front end, or inadequate manual disambiguation once potential false positives or negatives are identified, can both contribute to the error rate.
For providers attempting to access data from other organizations, these problems can be even more frustrating than usual, says The Sequoia Project in its 2015 framework for patient identity management, because data integrity shortfalls that occur elsewhere are not under the provider’s control.
Coordination between the HIM departments at both organizations, an HIE vendor or network shuttling the data back and forth, and both organizations’ EHR vendors can be almost prohibitively complex, especially when the two entities share a large patient population.
“Health data sharing introduces dependencies upon these independent organizations, and intertwines the workflows of the organizations, where no single organization has direct control over the other,” The Sequoia Project says.
“This plays heavily into cross-organizational diagnostics, manual fallback procedures when automated patient matching does not work, manual intervention to correct patient records, and manual intervention to gather consent.”
Organizations often resort to testing patient matching algorithms against a manually validated subgroup of shared patients, which can be time consuming as well as subject to the same human errors that plague automated identification techniques.
Developing a strategy to improve patient matching
It may not seem easy for organizations to find their way out of this complicated data integrity quagmire, but they do have several options for improving their governance strategies and untangling their crossed wires.
The Sequoia Project suggests first assessing an entity’s patient matching maturity, especially when considering data exchange across disparate facilities.
The interoperability initiative proposes a 0-4 scale, where the bottom rung indicates an unpredictable, ad hoc approach to patient matching that does not include any oversight and the highest level denotes an active data integrity program with engaged leadership and ongoing commitment to improvement.
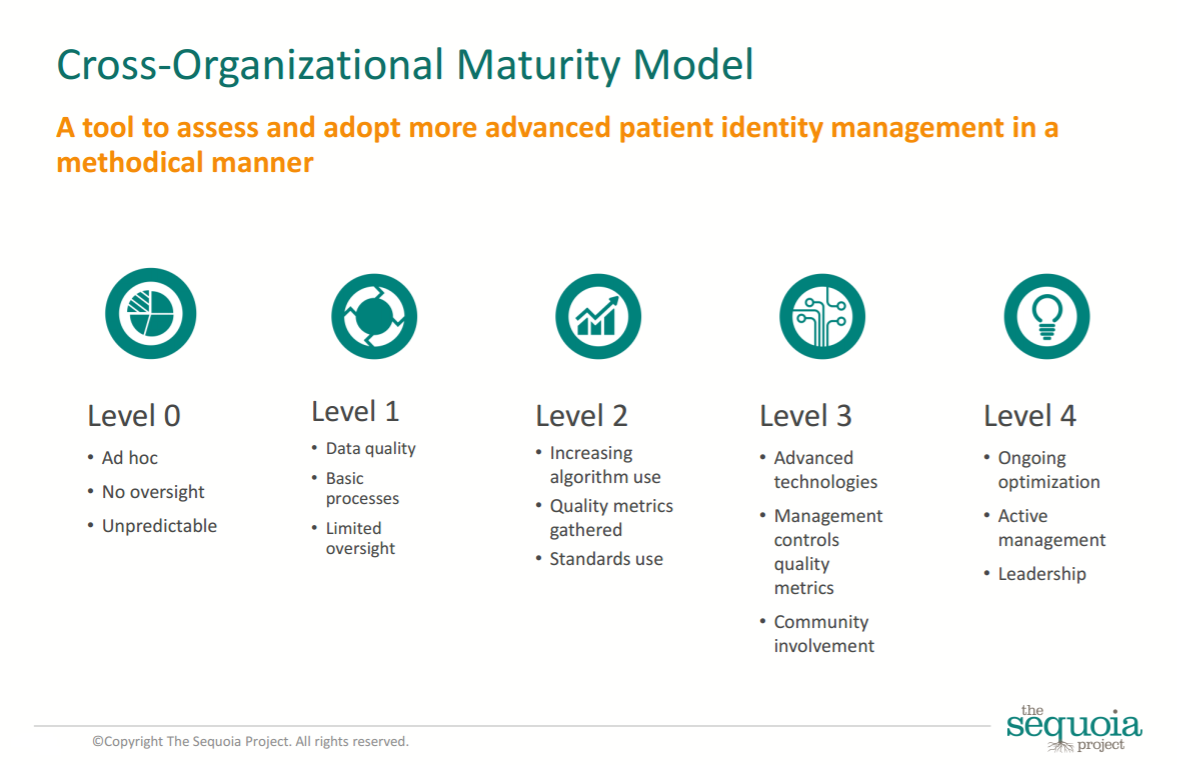
Source: The Sequoia Project
Organizations at the bottom end of the scale can experience match rates as low as 10 to 15 percent, The Sequoia Project notes, but top-performing health systems can consistently identify patients correctly up to 90 percent of the time.
Once an organization and its partners understands where they fall along the maturity scale, they can start to move forward with technical and governance changes to improve their percentages of correct matches.
“Simple process improvements such as data validity checking, normalization, and downstream data cleansing can increase patient matching rate to 60 or 70 percent,” the report says.
Organizations will need to rely on the expertise of health information management professionals to undertake a data integrity overhaul. The HIM department should conduct routine quality checks, AHIMA says.
These activities may include “daily, weekly, and monthly reporting on demographic changes made to patients, duplicates created, and feedback mechanisms,” AHIMA stated in 2016. “The process may also include a reconciliation process for temporary values as indicated with trauma, unknown, and newborn patients.”
READ MORE: Health Information Governance Strategies for Unstructured Data
Organizations may wish to dedicate staff time to collecting missing data from patients, either through direct phone calls, information reviews upon the next appointment, home mailings, or patient portals.
Providers should also monitor issues such as the turnover rate for registration staff, which may indicate the need for more robust training or regular refresher courses on how to correctly and uniformly input patient data upon an individual’s arrival.
Reaching the next level of accuracy may require providers to take a closer look at what algorithms they use and how those tools evaluate the usefulness of common demographic data elements.
HIM professionals at Intermountain Healthcare took a closer look at their EMPI, which contained more than 6.6 million patient records in 2016. Patient data tended to become incorrect at the rate of 1 percent per month, similar to other datasets such as provider directories or general mailing lists.
In order to better understand the reliability hierarchy of their available information, Intermountain asked the following questions about each element:
- How complete is the data? At what rate is this element captured appropriately in the record?
- Is this element likely to be correct? Is the value temporary (i.e., “Baby Smith”) and if so, is it a valid identifier?
- Is this trait distinctive enough to be used as a key identifier, or is it shared among a large group (i.e., “male” or “female”)?
- Is the data element structured or free text? Is it likely that the format is comparable across disparate systems?
- How much does the trait change over a patient’s lifetime? Is it variable, like a home address or likely to remain the same for an individual until death, such as a Social Security number?
Intermountain found significant variability in the completeness and usefulness of common identifiers, such as address, date of birth, phone numbers, and ethnicity or racial data.
While street addresses were collected 95 percent of the time, for example, they had a low level of distinctiveness, changed often, and were rarely entered in exactly the same format at different locations, leading to an insufficient level of comparability.
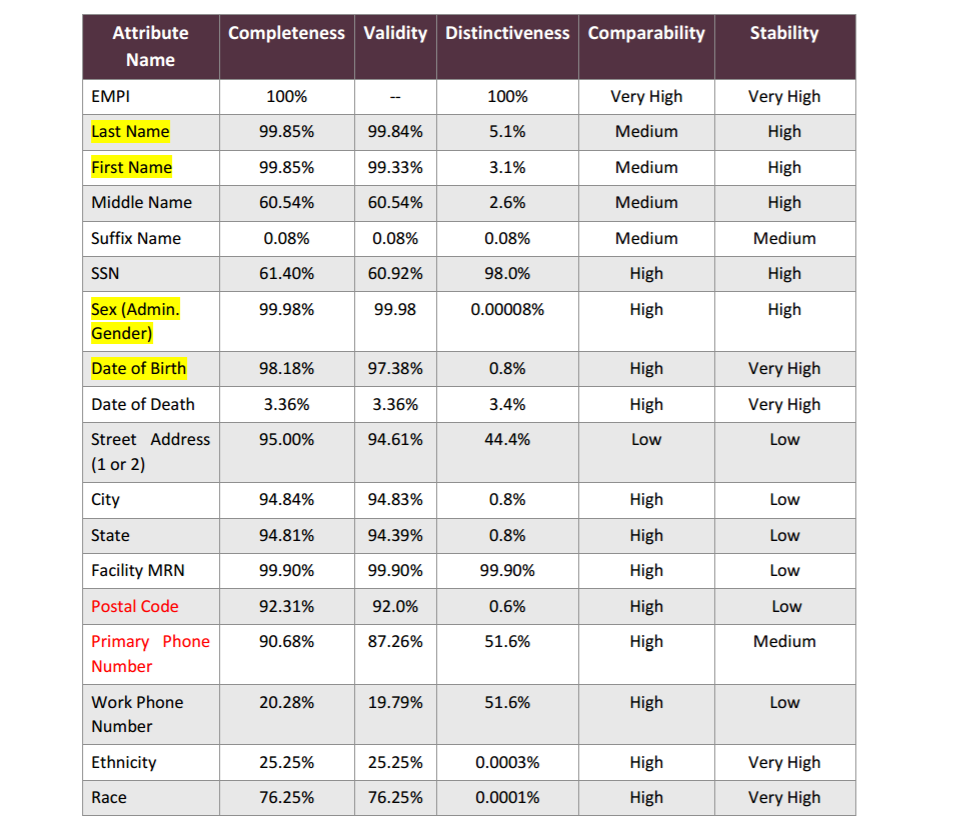
Source: The Sequoia Project
Social Security numbers, on the other hand, were only collected 61 percent of the time, yet were highly distinctive, very stable, and collected in a format that is easy to compare across disparate systems.
“But the SSN is fraught with other challenges including fraud, medical and financial identity theft, sharing by multiple individuals, and more,” The Sequoia Project points out.
“These issues are compounded by the fact that some organizations require the use of SSNs for matching purposes, and even have made internal assumptions that the SSN will be provided.”
Other organizations have taken the opposite approach and banned the collection of SSN data due to privacy concerns. If one provider in a local community has taken the first approach and another provider adheres to the second, then even the high reliability and repeatability of SSN data is rendered moot.
Instead of relying heavily on a single element, Intermountain used a combination of traits that produced a higher overall degree of correct matches.
Similar to the multi-factor identification string suggested by RAND Corporation, Intermountain found that a patient’s first name, last name, date of birth, gender, and last 4 SSN digits produced a uniqueness value of 99.7 percent. However, all of this information was available only 61 percent of the time.
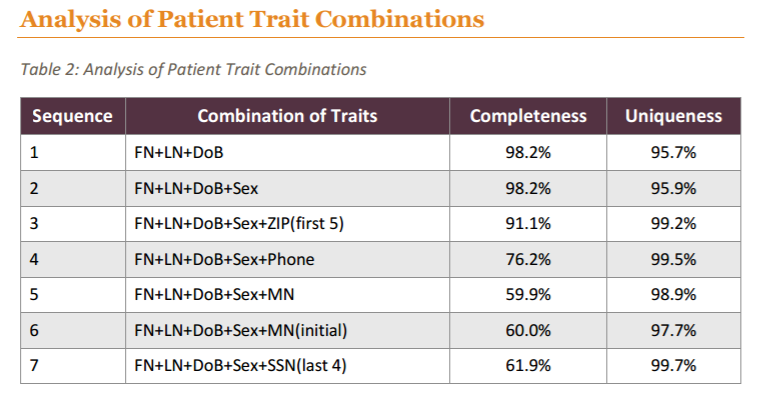
Source: The Sequoia Project
Restricting the list to just first name, last name, and birth date produced a unique match 95.7 percent of the time. All of those elements were available in 98.2 percent of cases. Adding gender and zip code reduced the completeness rate to 91.1 percent, but boosted the uniqueness factor past the 99 percent mark.
The health system found that the improving the completeness of a patient’s demographic record represents the single largest opportunity to immediately raise patient matching rates. Timeliness of the data, as well as consistent representations of names, dates, addresses, and other identifying elements, also contributed significantly to high rates of accuracy, even in the absence of a unique identification criteria.
In order for other organizations to achieve the laudable 95 percent match rate developed by Intermountain, providers will need to invest in a broad and detailed data governance roadmap that trains staff to input data correctly, collect as much information as possible, and confirm the accuracy of the data frequently.
The next steps towards uniformly reliable patient matching
Demographic-based patient matching algorithms will always have their shortcomings, since data integrity in electronic health systems will never be absolutely infallible.
Some healthcare organizations are looking to get around the problem by employing innovative biometric systems that scan a patient’s retinas, vein patterns, or fingerprints.
Distinguishing between the 2500 patients named Maria Garcia in Harris County is now accomplished with a palm scan, reported the Houston Chronicle. After a patient verifies her identity at the first encounter using a government-issued ID, she only needs to have her hand and her birth date available at subsequent appointments.
Other organizations are still hoping that the familiar litany of identifying demographic information will continue to contribute to reliable records.
CHIME has been a stalwart proponent of the idea that the healthcare system can develop better patient matching techniques. The professional organization is approaching the final stages of its $1 million challenge to develop a national patient ID strategy, recently tapping four innovative ideas to remain in contention for the prize.
The proposed solutions include the use biometrics, photos, behavioral data, blockchain, and FHIR to create a 100 percent reliable matching system. Winners will be announced in early November, CHIME says.
The Office of the National Coordinator added to the intrigue in May by offering up to $75,000 for a better matching algorithm that can be integrated into existing EHRs. The challenge aligns with the ONC’s 2015 Shared Nationwide Interoperability Roadmap, which counts inadequate patient matching as one of the nation’s top data exchange barriers.
The Pew Charitable Trusts aren’t offering a hefty cash prize, but are conducting their own research into the role of data standardization in matching improvements, Moscovitch said.
“We’re also examining several other approaches to improve patient matching, including how to put the patient at the center of the matching process,” he added. “There is also an effort to explore how to integrate patient perspectives into different patient matching approaches, including the use of unique identifiers and biometrics.”
Still other stakeholders are holding out hope that a national patient identifier (NPI) will someday come into existence.
READ MORE: National Patient Identifier May Cut “Silly Waste” in Healthcare
The NPI, written into HIPAA but blocked since 1999 by privacy-conscious Congressional leaders, is often cited as the single best solution to the industry’s patient matching woes.
Beth Israel Deaconess Medical Center CIO John Halamka, MD, MS, recently reiterated his support for a national patient identification system, and AHIMA has done the same.
Arguing for a “national voluntary patient safety identifier” in March of 2016, AHIMA President and CEO Lynne Thomas Gordon, MBA, RHIA, CAE, FACHE, FAHIMA, said that a voluntary patient identification system, created and controlled by patients themselves, would be a “complete and positive game-changer.”
“We encourage patients, healthcare professionals and the public to think about patient safety,”
she said. “We want to make healthcare safer, more efficient and more effective for everyone.”
RAND Corporation also incorporated the idea of a voluntary patient identifier into its 2008 paper, and even the ONC highlighted several private sector initiatives to create a national system.
Congress has not yet yielded to growing pressure from healthcare stakeholders to implement a universal system, but it has taken one small step towards easing its restrictions, said Moscovitch in a March blog post.
In the 21st Century Cures Act, a landmark interoperability bill passed at the end of 2016, Congress requires the Government Accountability Office to study the patient matching landscape and establishes a Health IT Advisory Committee to propose interoperability policies that include how to avoid duplicated or inaccurate records.
“While the 21st Century Cures Act will help efforts to understand and mitigate patient matching problems, real progress will require private and nonprofit health care systems, EHR vendors, and patient advocates to come together to develop a single, national solution.”
Cooperation across communities and a deeper understanding of the challenges of patient matching – and potential solutions – will allow stakeholders to improve data integrity, avoid patient harm, and deliver a higher quality experience to patients.
“The ability to share health data should be a fundamental part of a health care system that provides patients with reliable, high-quality, coordinated care,” said Pew. “The federal government, hospitals, clinicians, EHR vendors, and other stakeholders should work together to overcome interoperability challenges so that individuals are matched with their records, and physicians can use that data to improve patient health.”